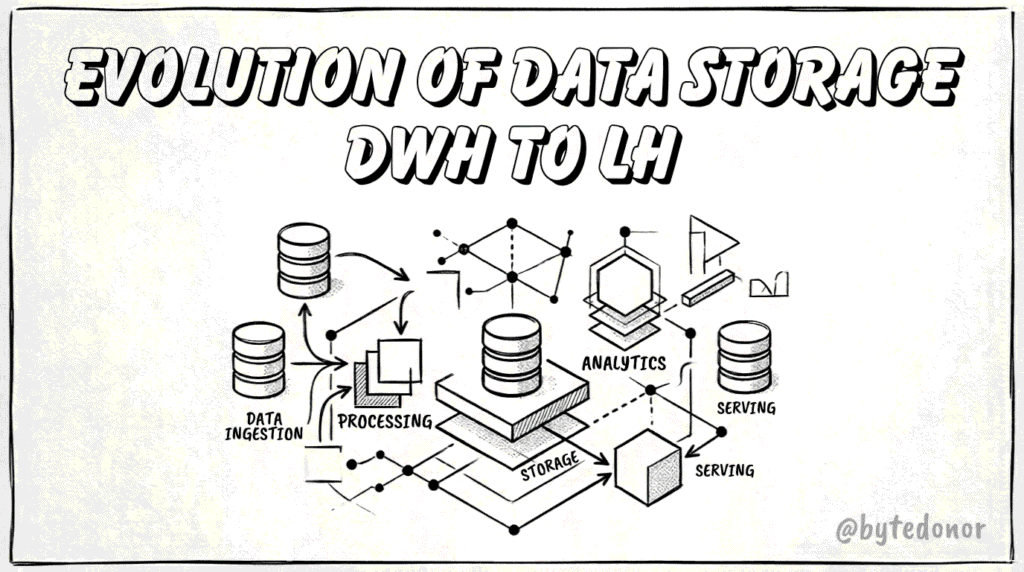
If you’ve spent any time looking into modern data infrastructure lately, you have probably noticed a dizzying parade of buzzwords. One year everyone is talking about moving everything to a data lake; the next, the Data lake is legacy, and you need a Data Lakehouse. Just as you wrap your head around that, concepts like data fabric and data mesh enter the chat.
It feels like trying to learn a language where the grammar changes every six months.
But behind the marketing hype and the shifting terminology, these concepts represent real solutions to recurring engineering problems. To build a solid foundation, we need to strip away the buzzwords and look at how data architecture evolved, what these patters actually do, and how they piece together in the real world.
Contents
What Exactly Is Data Architecture?
Like software architecture, if you ask five different engineers to define “Data Architecture,” you will probably get five different answers. There isn’t one universal, textbook definition. However, one of the most practical ways to think about it comes from Joe Reis and Matt Housley in their book, Fundamentals of Data Engineering:
Data Architecture is the design of systems to support the evolving data needs of an enterprise, achieved by flexible and reversible decisions reached through a careful evaluation of trade-offs.
Let’s put it in simple words, it is the operational blueprint for how an organization turns Raw data into Actionable insights. It governs everything that how data is collected (ingestion), where it sits (storage), how it gets cleaned up (transformation), and how it is ultimately delivered to the people who need it (serving).
The most critical word in this definition is Evolving. A great data architecture isn’t a rigid monument carved in stone; it is an agile framework built to adapt as a business grows and its demands change.
The Reality of Data Growth
In the early days of a startup, data is simple. It usually flows from a single production database. But as a company scales, that simplicity vanishes.
However, suddenly, you are managing dozens of Microservices, spinning up new internal applications, and integrating third-party tools like Salesforce, HubSpot, or Google Analytics. Every single one of these systems generates its own isolated stream of data.
Meanwhile, business teams are inherently hungry for insights. They know that more data means more opportunities to analyze customer behavior, spot inefficiencies, and optimize operations. To satisfy this hunger, organizations generally lean toward one of two overarching architectural philosophies: centralized or decentralized.
The Centralized Approach
For decades, the default strategy for managing data complexity has been centralization.
In a centralized architecture, all the disparate data streams from across the company are gathered, processed, and stored in one single, unified “place.” This central repository acts as the organization’s definitive source of truth.
Because when everything is under one roof, data management is typically handled by a core, specialized data team that oversees the infrastructure from end to end.
Historically, the pioneer of this concept was Bill Inmon, who famously defined this centralized repository as the Data Warehouse.
The Evolution of the Data Warehouse
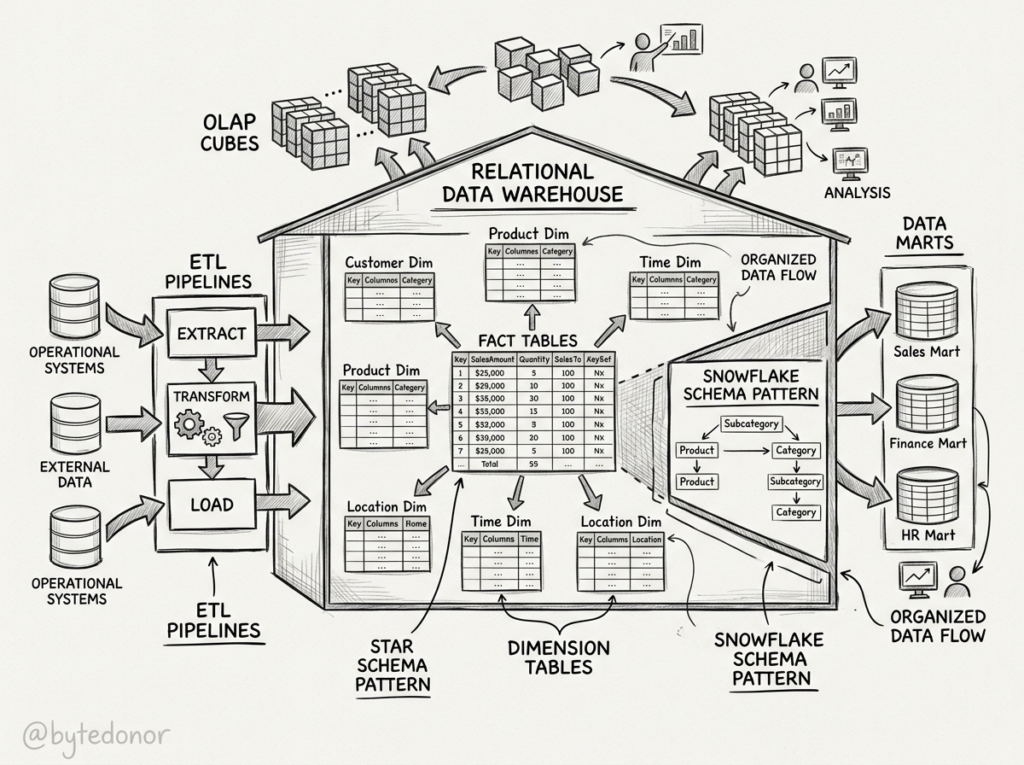
To understand where we are today, we have to look at how data warehousing started. In the early days, companies tried to build their data warehouses using traditional transactional databases (the same kind of databases that power application backends).
It didn’t take long to realize this was really a round-peg-in-a-square-hole situation. Transactional databases are designed to handle millions of tiny, fast queries (like updating a user’s profile picture or processing a single checkout).
Moreover, these are fundamentally not built to scan billions of rows at once just to tell an executive what total sales looked like last quarter. Running heavy analytics on a transactional system usually resulted in agonizingly slow reports—or worse, crashing the production app entirely.
The OLAP Boom and the Cloud
Everything changed in the 2000s and 2010s with the rise of dedicated OLAP (Online Analytical Processing) databases.
These modern engines were purpose-built for Analytics. Instead of reading data row-by-row, they processed data in massive columns, allowing them to scan and aggregate giant datasets at lightning speed. When Cloud data warehouses arrived on the scene, they combined this raw performance with “pay-as-you-go” pricing. Suddenly, companies didn’t need to buy million-dollar physical servers just to run complex queries; they could simply rent the computing power they needed, when they needed it.
Myth vs. Reality – The Problem with Structure
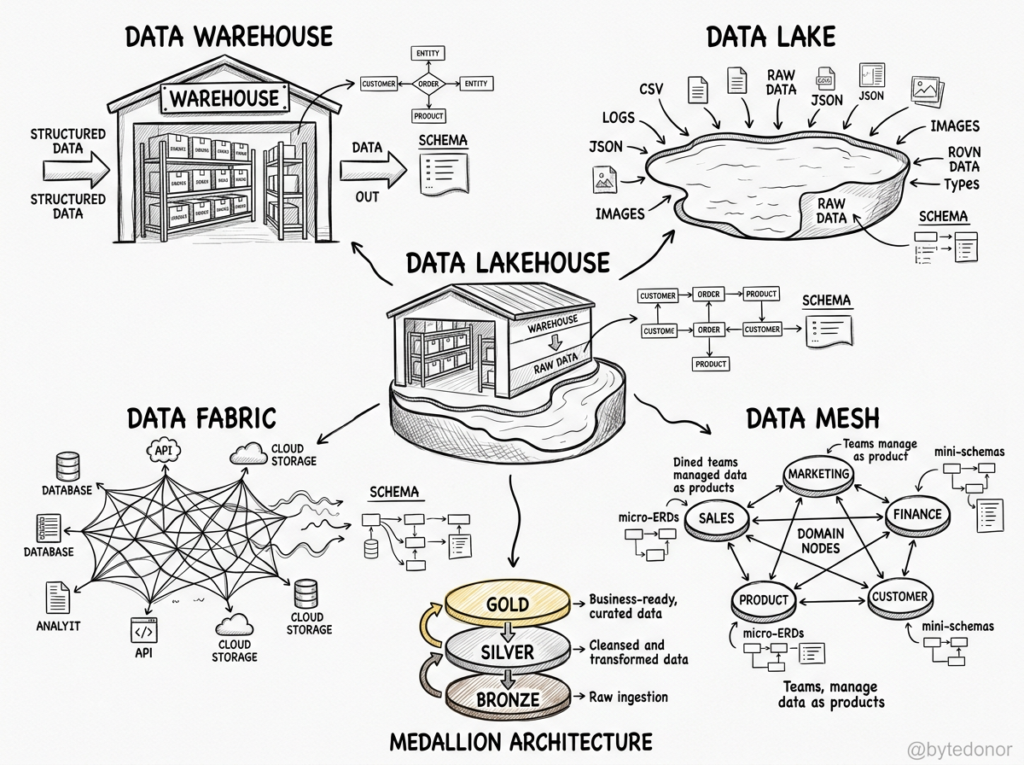
If you talk to data veterans, you’ll often hear that traditional relational data warehouses have a bad reputation. The common complaint? They are too rigid. Historically, if your data wasn’t neatly organized into strict rows and columns (structured data), a data warehouse couldn’t handle it. This rigid requirement was actually the primary catalyst for the creation of the Data Lake (which we will look at next).
However, it is important to separate past limitations from modern realities. Today’s cloud data warehouses have evolved significantly. Modern platforms like Snowflake and Google BigQuery have robust, native support for semi-structured data (like JSON files) and can even store, catalog, and retrieve completely unstructured data like text documents, images, and audio files.
So, the line between what a warehouse can and cannot hold has blurred completely.
The Rise of the Data Lake
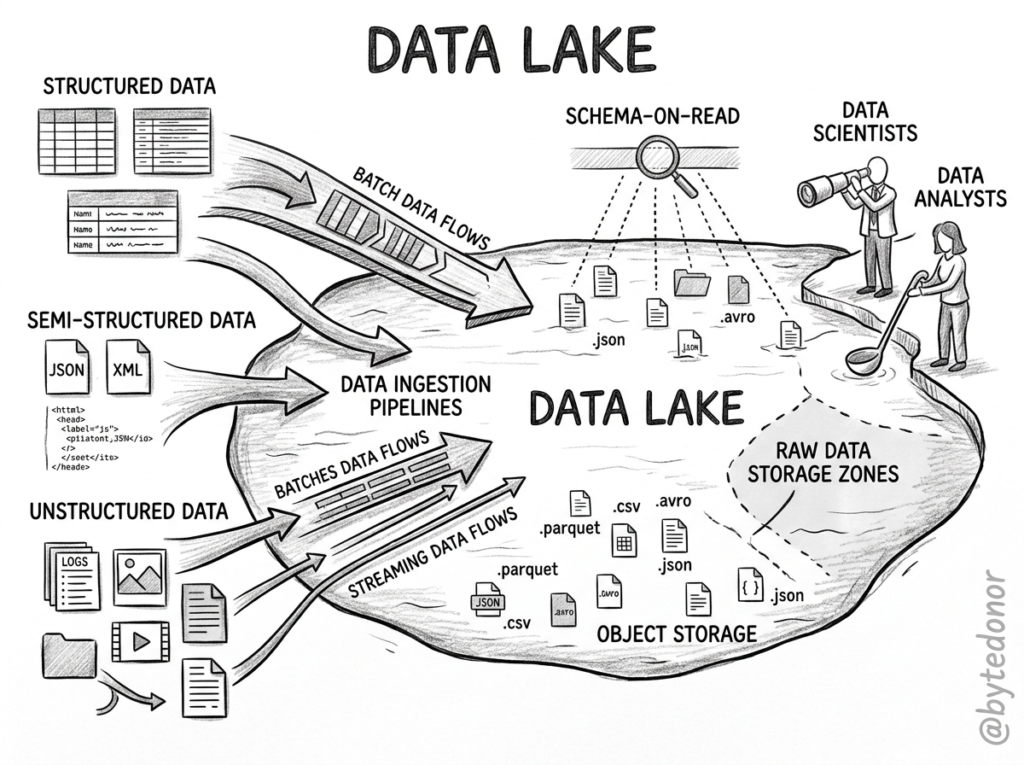
To solve the rigidity problem of traditional warehouses, a new architectural concept emerged, ‘The Data Lake.
The core philosophy of a data lake is simple. Dump everything in first and worry about the structure later. Instead of forcing data into neat rows and columns before saving it, a data lake allows organizations to store vast amounts of data in its raw, native format. Whether it is structured database exports, semi-structured JSON logs, or completely unstructured files like images and videos, it all goes into a massive, low-cost storage layer (historically powered by HDFS, and later by cloud object storage like AWS S3 or Google Cloud Storage).
Here, This approach introduced the concept of Schema-on-Read. You don’t need a predefined blueprint (schema) to store the data; you only apply a structure when you pull the data out to analyze it.
When Lakes Turn into Swamps
Because data lakes made it incredibly cheap and easy to store everything, organizations initially thought
“Why do we even need a data warehouse? Let’s just run all our analytics directly on top of the data lake.”
It sounded perfect in theory. But in practice, it was a disaster.
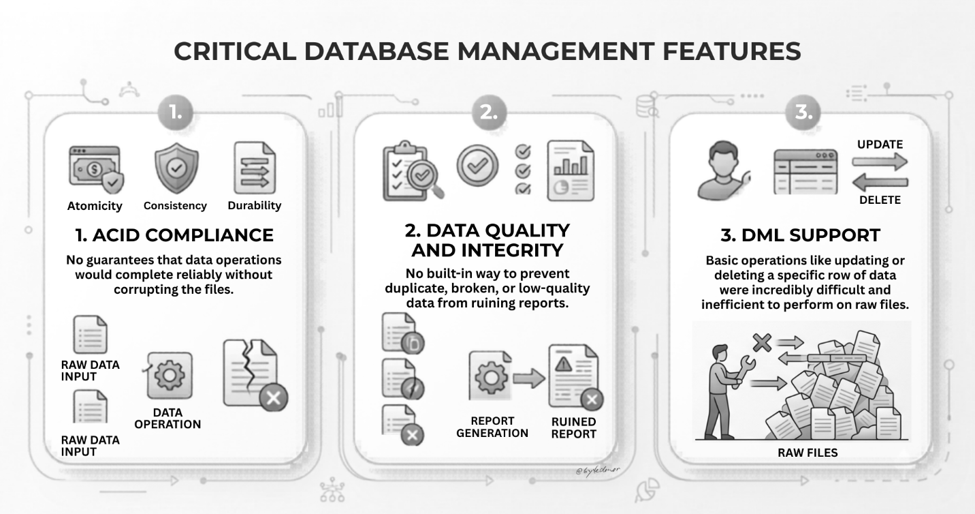
Without the strict guardrails of a traditional database, these lakes quickly degenerated into Data Swamps. Because anyone could dump files anywhere, finding the right dataset became nearly impossible. Even worse, early data lakes lacked critical database management features, including:
The Hybrid Solution
Realizing that neither a pure data warehouse nor a pure data lake could solve all their problems, architects arrived at a compromise. They combined them.
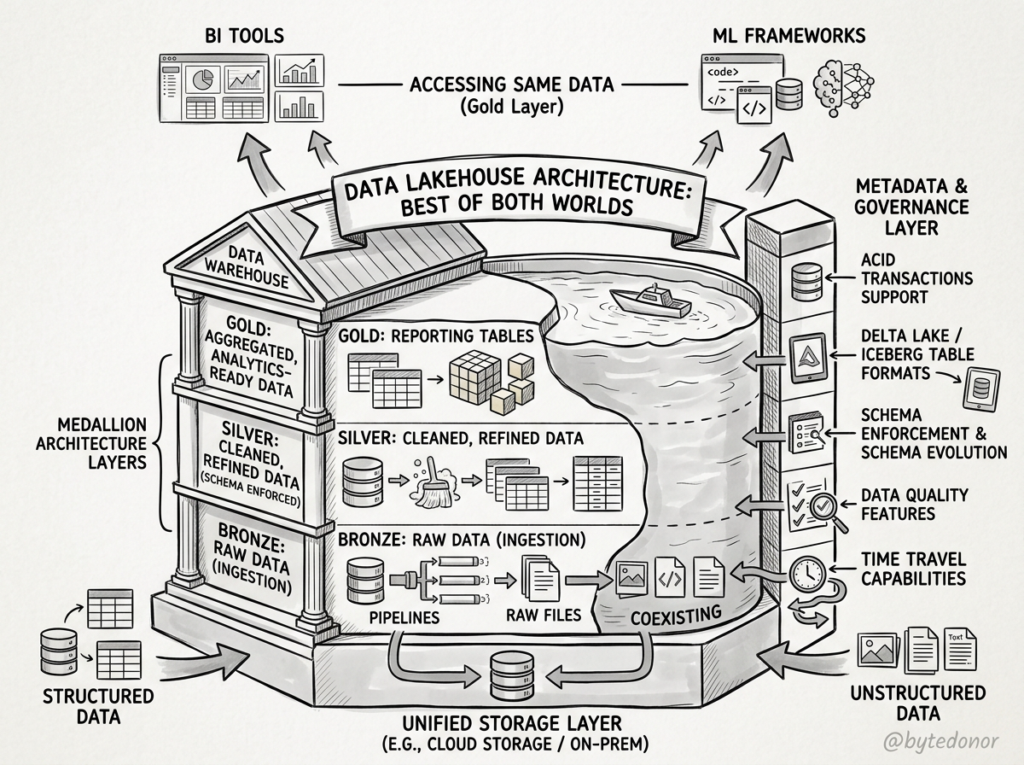
From the mid-2000s through the 2020s, this hybrid setup became the gold standard for enterprise data architecture.
In this unified architecture, the two systems work as a Team:
- The Data Lake acts as the staging ground. It ingests and holds all raw, unstructured, and high-volume data cheaply.
- The Data Warehouse sits downstream. A specialized data team cleans, structures, and transforms a curated subset of that raw data, moving it into the warehouse where business analysts can query it safely and quickly.